# リレーショナルDBを触ってみる
# <事前準備>
- Dockerがインストールされていること
- PowerShellが利用できる状態であること
- インターネットに接続できていること
# PostgreSQLについて
# 呼び方
- 「Post-Gres-Q-L(ポスト・グレス・キュー・エル) 」または「Postgres(ポストグレス)」と発音します。
- PostgreSQL とは何ですか?その呼び方は? Postgresとは? (opens new window)
- 省略して「ポスグレ」と呼ばれることもあります。
# 日本PostgreSQLユーザ会
- 日本PostgreSQLユーザ会 (opens new window)
- 日本国内でPostgreSQLデータベースを使用するユーザーのコミュニティおよび組織です。
- このユーザ会は、PostgreSQLに関心を持つ人々が情報共有や交流を行い、技術的な知識を向上させることを目的としています。
# バージョン体系(超抜粋)
※8.0よりも前のバージョン(6.0や7.0)については省略します。
| メジャーバージョン | リリース日 | 最新マイナー版 | 最新版リリース日 | サポート期限 |
|---|---|---|---|---|
| 8.0 | 2005/11/8 | 8.0.26 | 2010/10/4 | 2010/10/1 |
| 8.1.x~8.4.x | 省略 | 省略 | 省略 | 省略 |
| 9.0 | 2010/9/20 | 9.0.23 | 2015/10/8 | 2010/10/8 |
| 9.1.x~9.6.x | 省略 | 省略 | 省略 | 省略 |
| 10 | 2017/10/5 | 10.23 | 2022/11/10 | 2022/11/10 |
| 11 | 2018/10/18 | 11.22 | 2023/11/9 | 2023/11/9 |
| 12 | 2019/10/3 | 12.22 | 2024/11/21 | 2024/11/21 |
| 13 | 2020/9/24 | 13.21 | 2025/5/8 | 2025/11/13 |
| 14 | 2021/9/30 | 14.18 | 2025/5/8 | 2026/11/12 |
| 15 | 2022/10/13 | 15.13 | 2025/5/8 | 2027/11/11 |
| 16 | 2023/9/14 | 16.9 | 2025/5/8 | 2028/11/9 |
| 17 | 2024/9/26 | 17.5 | 2025/5/8 | 2029/11/8 |
※バージョン体系がPostgreSQL10より変更されました。
Postgresql 10以前 ⇒ 9.0 .23
9.0の部分がメジャーバージョンで23がマイナーバージョンとなります。
Postgresql 10以降 ⇒ 10 .22
10の部分がメジャーバージョンで22がマイナーバージョン となります。
# ライセンス
PostgreSQLは、オープンソースのリレーショナルデータベース管理システムです。
そのライセンスは、PostgreSQL Global Development Group(PGDG)によって開発されたもので以下の2つのライセンスオプションが提供されています。
PostgreSQLライセンス(PostgreSQL License これは、PostgreSQLプロジェクトが採用している独自のライセンスです。 このライセンスは、商用利用や非商用利用、修正や再配布を含むあらゆる使用形態に対して、 自由かつ無償で利用することを許可しています。また、ソースコードの利用や変更、派生物の作成、 バイナリ形式での再配布なども可能です。そのため、PostgreSQLを自由に使用し、変更や拡張を行い、 プロジェクトや製品に組み込むことができます。
MIT(マサチューセッツ工科大学)ライセンス PostgreSQLプロジェクトは、PostgreSQLライセンスに加えて、一部のコンポーネントについてはMITライセンスも採用しています。 MITライセンスは、商用利用や非商用利用、修正や再配布を含むあらゆる使用形態に対して、自由かつ無償で利用することを許可しています。 ただし、著作権表示および本許諾表示をソフトウェアのすべての複製または重要な部分に記載しなければならず、作者または著作権者は、ソフトウェアに関してなんら責任を負わない。
# ハンズオン研修 【データベースに触れてみよう】
# 0. PostgreSQL環境準備
本演習にて入力するコマンドはおおきく分けて以下の3つにわかれているため、入力する場所には注意する必要があります。
1.Linux環境 【 $ 表示のプロンプト】
→ ★0-1、★0-2 、★0-3 での入力先となります。2.コンテナ環境 【 root@xxx から始まるプロンプト】
→ ★0-4 ★1-1、及び★A-1、★A-2、★B-1先頭行、★B-2 での入力先となります。3.PostgreSQL環境 【 postgres=# から始まるプロンプト】
→ ★1-2~演習問題まで及び★B-1drop文 の入力先となります。
※出力イメージと異なるような結果が表示された際には入力場所をご確認ください。
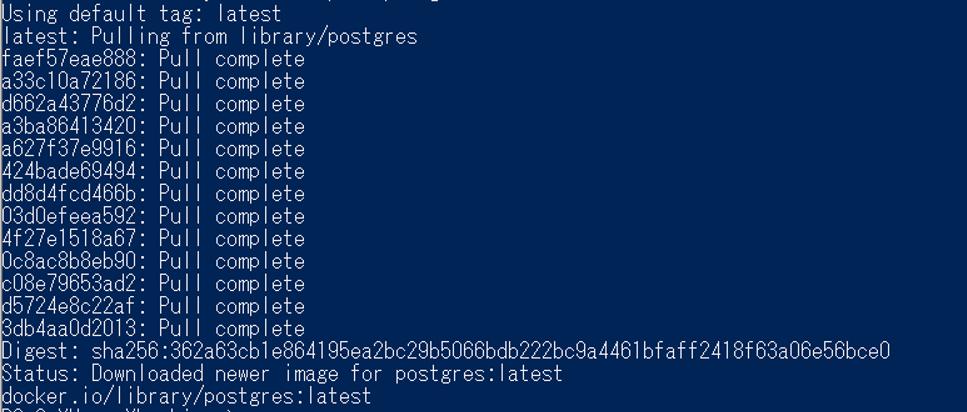
# ★0-1 PostgreSQL環境のダウンロード
以下のコマンドを入力し、PostgreSQL環境をダウンロードします。
docker pull postgres
◎出力イメージ
# ★0-2 コンテナ起動
以下のコマンドを入力し、コンテナ(PostgreSQLも起動します)環境を起動させます。
docker run --name some-postgres -e POSTGRES_PASSWORD=postgres -d postgres
◎出力イメージ

※正常に起動すると上記のような64文字の文字列(値は各自で異なります)が表示されます。
# ★0-3 コンテナ接続
以下のコマンドを入力し、コンテナに接続します。
docker exec -it some-postgres /bin/bash
◎出力イメージ

※接続に成功すると上記のような最後に「#」が付いた状態で表示されます。
※「root@」以降の文字列は各自で異なります。
# ★0-4 ロケールの確認
本講義で使用する言語「en_US.utf8」が表示されることを確認します。
locale -a
◎出力イメージ

# 1. データベースへ接続してみよう
# ★1-1 DB接続
PostgreSQLデータベースに接続し、SQLを発行するためには「psql」というツールを利用します。
OSユーザ「postgres」にスイッチ後、データベースに接続してみます。
su - postgres
psql -h localhost -p 5432 -d postgres -U postgres
2
◎出力イメージ

※プロンプトが「postgres=#」に変更されることを確認します。
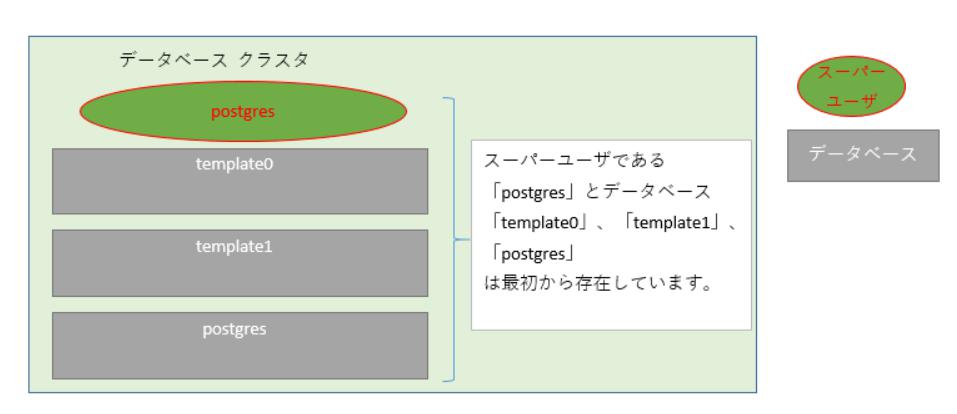
# ★1-2 データベース確認
以下コマンド(エンマーク 英小文字のエル プラス)を実行します。
\l+
◎出力イメージ

現時点ではデータベースが3つ表示されています。
イメージ図としては以下(グレーの四角がデータベース)です。
# 2. ユーザ(ロール)を作成してみよう
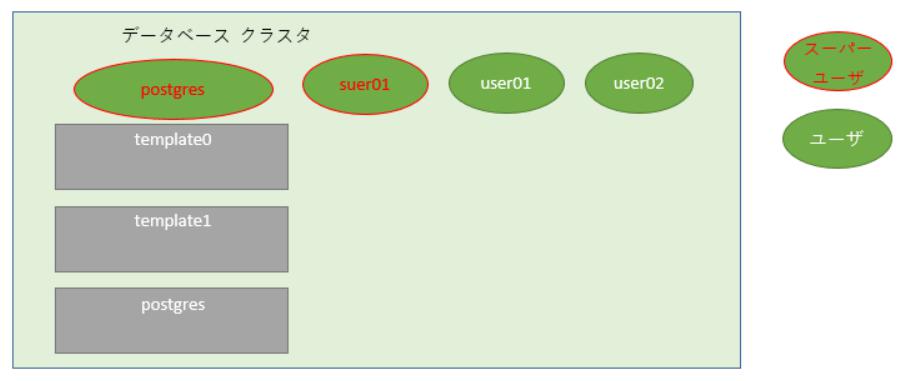
# ★2-1 ユーザ作成
デフォルトで作成されているユーザ「postgres」以外に以下の3ユーザを作成します。
- ユーザ「user01」を作成します
- ユーザ「user02」を作成します
- スーパーユーザ「suser01」を作成します
作成後は以下のようなイメージ(緑色の丸枠がユーザ)となります。
「user01」の作成
create role user01 with login password 'user01';
「user02」の作成
create user user02 with password 'user02';
「suser01」の作成
create role suser01 with superuser login password 'suser01';
※全て「CREATE ROLE」と表示されることを確認します。
※作成後、スーパーユーザ(suser01)でログインしなおしましょう。
\connect - suser01
※PostgreSQLにおいて「ユーザ」と「ロール」は厳密には異なるため、上記のように2種類のコマンドが存在しますが、
今回は「ユーザ」と「ロール」は同じものであると考えましょう。
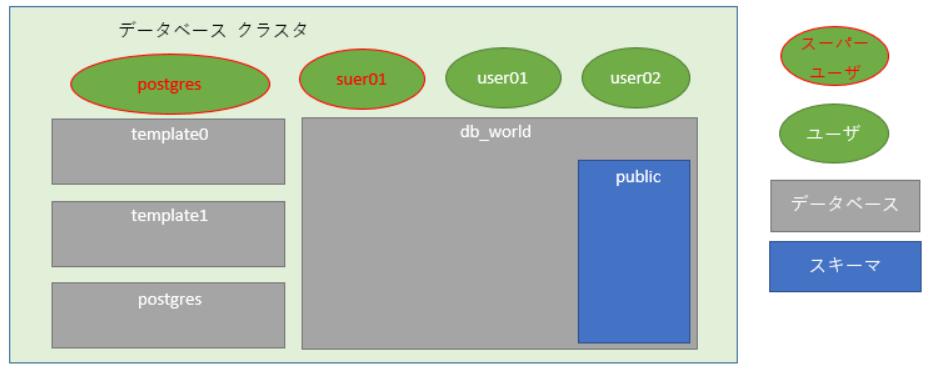
# 3. データベースを作成してみよう
「create database」文を利用しデータベースを作成します。
ここでは、データベース名を「db_world」と指定し、template0を使用してデータベースを作成しています。
※「public」スキーマも同時に作成されます。 (スキーマは後述しますが、「public」スキーマは全ユーザが自由に使えるスキーマです)
# ★3-1 データベースの作成
create database db_world owner = suser01 template = template0 encoding = 'UTF8' lc_collate = 'en_US.utf8' lc_ctype = 'en_US.utf8';
※「CREATE DATABASE」と表示されることを確認します。
# ★3-2 データベースへの接続
次STEPの準備として、作成したデータベース(db_world)にスーパーユーザ(suser01)で接続します。
\connect db_world suser01
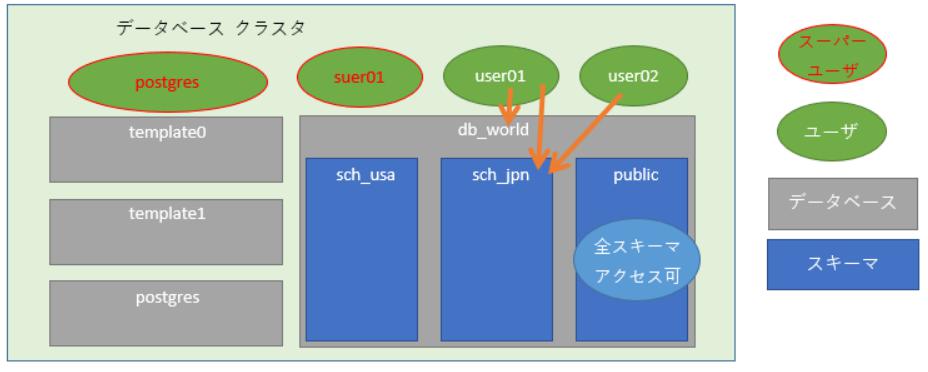
# 4. スキーマを作成し権限を付与してみよう
データベース内にスキーマ(青色の四角枠)を作成し、ユーザに利用権限(オレンジの矢印)を付与します。
スキーマとは、テーブルやインデックスといったオブジェクトを配置する領域です。
※「public」スキーマはDB作成時に作られており、テーブル等の作成時にスキーマ名を省略するとこの領域に配置されます。
# ★4-1 スキーマの作成
以下の2つのスキーマを作成してみましょう。 以下の例では2つのスキーマの所有者に「suser01」を指定しています。
create schema sch_jpn authorization suser01;
create schema sch_usa authorization suser01;
2
※「CREATE SCHEMA」と表示されることを確認してください。
# ★4-2 権限付与
所有者以外がスキーマにオブジェクトを配置するためには権限が必要です。
grant all privileges on database db_world to user01;
grant all privileges on schema sch_jpn to user01;
grant all privileges on schema sch_jpn to user02;
2
3
※「GRANT」と表示されることを確認してください。
この権限の追加により
- 「user01」は「db_world」データベース、「sch_jpn」スキーマ内への全権限を有します。
- 「user02」は「sch_jpn」スキーマ内への全権限を有します。
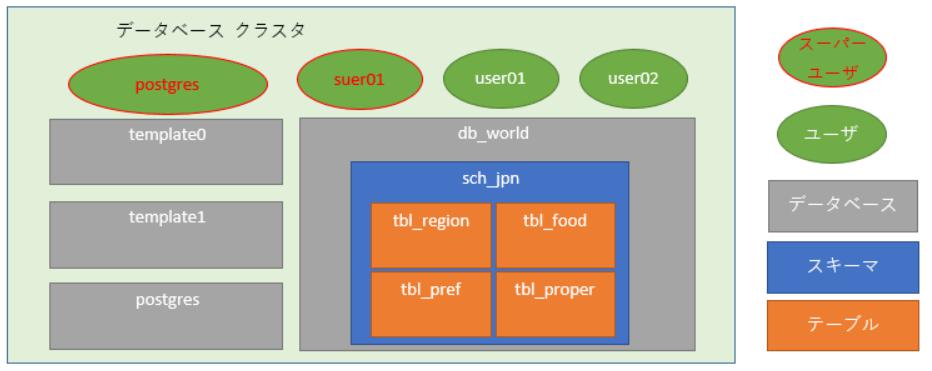
# 5. テーブルを作成してみよう
上記にて作成した「sch_jpn」スキーマ内にテーブル(オレンジ色の四角枠)を作成します。
# ★5-1 テーブル作成
「user01」で接続し、テーブルを作成します。
以下ではテーブル作成時に主キー(PRIMARY KEY)を作成しています。
主キーを作成した列には同じ値とnullを挿入できなくなります。
※スキーマ(sch_jpn)は必ず指定してください。省略してしまうと「public」スキーマに作成されます。
\connect db_world user01
create table sch_jpn.tbl_region(id_reg serial,reg_name varchar(40), PRIMARY KEY (id_reg));
create table sch_jpn.tbl_pref(id_pref serial,pref_name varchar(40),id_reg int, PRIMARY KEY (id_pref));
create table sch_jpn.tbl_food(id_fd serial,fd_name varchar(40),price int, PRIMARY KEY (id_fd));
create table sch_jpn.tbl_proper(id_user serial,username varchar(40),id_pref int,id_fd int, PRIMARY KEY (id_user));
2
3
4
5
6
※「CREATE TABLE」と表示されることを確認してください。
※テーブルを削除するコマンドは「drop table <テーブル名>」となります。
# 6. テーブルにデータを登録してみよう(insert into ~ values~)
# ★6-1 データの登録
上記で作成したテーブルにデータを登録します。
データを追加するコマンドはinsert文となります。
insert into sch_jpn.tbl_region(reg_name) values ('hokkaido');
insert into sch_jpn.tbl_region(reg_name) values ('tohoku');
insert into sch_jpn.tbl_region(reg_name) values ('kanto');
insert into sch_jpn.tbl_region(reg_name) values ('chubu');
insert into sch_jpn.tbl_region(reg_name) values ('kinki');
insert into sch_jpn.tbl_region(reg_name) values ('shikoku');
insert into sch_jpn.tbl_region(reg_name) values ('kyushu');
insert into sch_jpn.tbl_pref(pref_name,id_reg) values ('hokkaido',1);
insert into sch_jpn.tbl_pref(pref_name,id_reg) values ('yamanashi',4);
insert into sch_jpn.tbl_pref(pref_name,id_reg) values ('osaka',5);
insert into sch_jpn.tbl_pref(pref_name,id_reg) values ('nagasaki',7);
insert into sch_jpn.tbl_pref(pref_name,id_reg) values ('tokyo',3);
insert into sch_jpn.tbl_pref(pref_name,id_reg) values ('chiba',3);
insert into sch_jpn.tbl_food(fd_name,price) values ('hamburger',500);
insert into sch_jpn.tbl_food(fd_name,price) values ('ramen',1500);
insert into sch_jpn.tbl_food(fd_name,price) values ('takoyaki',800);
insert into sch_jpn.tbl_food(fd_name,price) values ('gyoza',350);
insert into sch_jpn.tbl_proper(username,id_pref,id_fd) values ('suzuki',1,1);
insert into sch_jpn.tbl_proper(username,id_pref,id_fd) values ('satou',2,4);
insert into sch_jpn.tbl_proper(username,id_pref,id_fd) values ('tanaka',3,2);
insert into sch_jpn.tbl_proper(username,id_pref,id_fd) values ('ito',4,3);
insert into sch_jpn.tbl_proper(username,id_pref,id_fd) values ('watanabe',5,4);
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
※全て「INSERT 0 1」と表示されることを確認してください。
# 7. データを参照してみよう(select ~ from ~)
# ★7-1 データの参照
テーブルに登録されているデータを参照します。データはSELECT文にて参照します。
※「*」を指定するとテーブルのカラム(列)全てを指定したことと同義になります。
〇7-1-1. 入力コマンド
select * from sch_jpn.tbl_region;
●7-1-1. 出力結果
id_reg | reg_name
--------+----------
1 | hokkaido
2 | tohoku
3 | kanto
4 | chubu
5 | kinki
6 | shikoku
7 | kyushu
(7 rows)
2
3
4
5
6
7
8
9
10
〇7-1-2. 入力コマンド
select * from sch_jpn.tbl_pref;
●7-1-2. 出力結果
id_pref | pref_name | id_reg
---------+-----------+--------
1 | hokkaido | 1
2 | yamanashi | 4
3 | osaka | 5
4 | nagasaki | 7
5 | tokyo | 3
6 | chiba | 3
(6 rows)
2
3
4
5
6
7
8
9
〇7-1-3. 入力コマンド
select * from sch_jpn.tbl_food;
●7-1-3. 出力結果
id_fd | fd_name | price
-------+-----------+-------
1 | hamburger | 500
2 | ramen | 1500
3 | takoyaki | 800
4 | gyoza | 350
(4 rows)
2
3
4
5
6
7
〇7-1-4. 入力コマンド
select * from sch_jpn.tbl_proper;
●7-1-4. 出力結果
id_user | username | id_pref | id_fd
---------+----------+---------+-------
1 | suzuki | 1 | 1
2 | satou | 2 | 4
3 | tanaka | 3 | 2
4 | ito | 4 | 3
5 | watanabe | 5 | 4
(5 rows)
2
3
4
5
6
7
8
# ★7-2
テーブルから条件を指定 (where句)してデータを抽出します。
〇7-2-1. 入力コマンド
select * from sch_jpn.tbl_pref where id_reg=3;
●7-2-1. 出力結果
id_pref | pref_name | id_reg
---------+-----------+--------
5 | tokyo | 3
6 | chiba | 3
(2 rows)
2
3
4
5
6
# ★7-3 複数のテーブルからのデータ参照
複数のテーブルを結合しデータを抽出します。
〇7-3-1. 入力コマンド
select
pp.username,
pr.pref_name,
rg.reg_name,
fd.fd_name
from
sch_jpn.tbl_region rg,
sch_jpn.tbl_pref pr,
sch_jpn.tbl_food fd,
sch_jpn.tbl_proper pp
where
pp.id_pref=pr.id_pref and
pp.id_fd=fd.id_fd and
pr.id_reg=rg.id_reg
ORDER BY
pp.username
;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
●7-3-1. 出力結果
username | pref_name | reg_name | fd_name
----------+-----------+----------+-----------
ito | nagasaki | kyushu | takoyaki
satou | yamanashi | chubu | gyoza
suzuki | hokkaido | hokkaido | hamburger
tanaka | osaka | kinki | ramen
watanabe | tokyo | kanto | gyoza
(5 rows)
2
3
4
5
6
7
8
# 8. データを更新してみよう(update ~ set ~)
# ★8-1 データの更新
データを変更するには「update」文を使用します。
update sch_jpn.tbl_pref set id_reg=4 where id_pref=2;
◆変更されているか確認してみよう。
⇒ 上記で使用したSELECT文を使い「tbl_pref」を参照してください。
# 9. データを削除してみよう(delete from ~)
# ★9-1 データの削除
データを削除するには「delete」文を使用します。
delete from sch_jpn.tbl_food where fd_name='ramen';
◆削除されているか確認してみよう。
⇒ 上記で使用したSELECT文を使い「tbl_food」を参照してください。
# 演習問題
# 問1)自分の好きな食べ物を「tbl_food」テーブルに登録し、そのデータを使って自分の情報をプロパー「tbl_proper」テーブルに登録してください
hint: insert into ~ values ~
# 問2)問1で追加したデータを参照してください(2テーブルを確認してください)
hint: select ~ from ~ where ~
# 問3)「tbl_proper」の中に存在している「tanaka」さんを「ikeda」さんに変更し、確認してください
hint: update ~ set ~
# 問4)「tbl_food」から「takoyaki」のみを削除し、確認してください
hint: delete from ~ where ~
▼▼▼▼▼▼▼▼▼▼▼▼▼以降、時間がある人向け▼▼▼▼▼▼▼▼▼▼▼▼▼
# A.バックアップ
# ★A-1. データベース バックアップ準備
バックアップデータの保管先へ移動します。
su - postgres
cd /tmp
2
# ★A-2. データベースのバックアップ
ここでは、2通りのバックアップを試してみます。
# ★A-2-1 plain形式での出力 (人間が見て分かるような結果が出力されます)
pg_dump -U suser01 -d db_world --format=p --create --file db_world_db.sql
cat db_world_db.sql
2
3
# ★A-2-2 バイナリ形式での出力
pg_dump -U suser01 -d db_world --format=c --create --file db_world_db.custom
ls -l
2
3
◎出力結果
total 20
-rw-r--r-- 1 postgres postgres 9710 Jul 10 12:00 db_world_db.custom
-rw-r--r-- 1 postgres postgres 7561 Jul 10 11:59 db_world_db.sql
2
3
# B.リストア
# ★B-1. データベース削除
データベースが破損したという仮定で、データベースを削除します。
psql -h localhost -p 5432 -d postgres -U postgres
\l
drop database db_world;
\l
\q
2
3
4
5
6
7
8
# ★B-2. データベースをリストア
データベースが削除されているため、「db_world」データベースを作成し、
「db_world_db.custom」を使ってリストアします。
createdb --template=template0 --encoding='UTF8' --lc-collate='en_US.utf8' --lc-ctype='en_US.utf8' db_world
pg_restore -v -c -d db_world /tmp/db_world_db.custom
psql -h localhost -p 5432 -d postgres -U postgres
\l
\q
2
3
4
5
6
7
8
この操作にてバックアップ取得時の状態へ復旧します。
※この他にもバックアップ取得時点ではなく、障害発生直前にまでリカバリできる
バックアップコマンド(pg_basebackup)も存在しますがここでは割愛します。
# PostgreSQL環境の停止について
Docker runコマンド実行の際に -d optionをつけている(back ground実行)ため、
★0-3 コンテナ接続
で 開いていた bash で exit してもPostgreSQL(コンテナ)環境は終了しません。
演習が終わりましたらstopコマンドにて停止させてください。
psコマンドにてstatus列 が Exited になっていれば停止となります。
※再度利用する際には docker start some-postgres にて起動可能させます。
docker stop some-postgres
docker ps -a
2
3
以上